

この記事は、もともとCybersecurity Diveに掲載されたものです。
現代の脅威ハンティングを支えるデータ中心の基盤
サイバーセキュリティの分野では、AIが脅威ハンティングの未来であると言われています。しかし実際には、多くのAIは本来の能力を十分に発揮できていないのが現状です。研究者たちは、AIモデルの性能はデータパイプラインの質に依存すると指摘しています。この原則は、学術的な機械学習にとどまりません。サイバーセキュリティにも同じように強く当てはまります。AI、自動化、または人間による調査を活用した脅威ハンティングは、その基盤となるデータインフラの品質に左右されます。
多くの場合、セキュリティチームは、データそのものというより根本的な課題に対処しないまま、既存のデータレイク上にAIを構築したり、新しい検知モデルをチューニングしたりすることに注力しています。エンドポイント、クラウド、アイデンティティ、SaaS、コードリポジトリなど、接続されていないシステム間でテレメトリがサイロ化されていると、アナリストは断片的な情報からコンテキストをつなぎ合わせることになります。適切な変換を行わずにすべてのデータを同じプラットフォームに集約すると、人間とAIの双方に過大な負荷がかかる可能性があります。どれほど高度なアルゴリズムであっても、不完全または不整合なデータを克服することはできません。不十分な入力に基づいて学習または動作するAIは、常に不十分な結論を導き出します。人間主導でAIを活用する脅威ハンティングも例外ではありません。

統合データが重要な理由
統合され、相関付けされたデータプラットフォームは、状況を大きく変えます。すべてのデータを1か所に集約することでノイズが減り、個々のシステムでは見えにくいパターンを把握できるようになります。また、この情報を事前に変換し、相関付けておくことで、大規模言語モデルやその他のAI主導ツールでも活用しやすくなります。構造やコンテキストを理解するために計算リソースやトークンを浪費するのではなく、AIは実際の挙動を理解することに集中できます。コンテキストが誤っていたり大きすぎたりすると、結果の品質が低下しがちです。
統合データにより、関連するアイデンティティも自然に浮かび上がります。1人のユーザーが、AWSではIAMプリンシパル、GitHubではコミッター、Google Workspaceではドキュメント所有者として表示され、それぞれまったく異なる名前で記録されている場合があります。これらのシグナルを1つだけ見ても、得られるのは断片的な情報にすぎません。しかし、それらをまとめて見ることで、行動の全体像が明確になります。Google Workspaceから数十件のファイルをダウンロードする行為は、単独では不審に見える程度かもしれません。しかし、同じアイデンティティが数分後にパブリックS3バケットを作成し、さらに数十件のリポジトリを個人用ノートPCにクローンしていた場合、そのアクティビティは明確に悪意あるものとなります。
相関による脅威ハンティング
ログ、設定、コードリポジトリ、アイデンティティシステムのデータがすべて1か所に集約されていると、これまで数時間かかっていた、あるいは不可能だった相関分析を即座に行えるようになります。たとえば、盗まれた短期間有効な認証情報に依存するラテラルムーブメントは、検知されるまでに複数のシステムを横断することがよくあります。侵害された開発者用ノートPCが、複数のIAMロールを引き受け、新しいインスタンスを起動し、内部データベースにアクセスする可能性があります。エンドポイントログからはローカル環境での侵害は分かりますが、IAMとネットワークデータがなければ、侵入範囲を証明することはできません。
同様に、攻撃者が侵害されたGitHub Actionsトークンを使用してクラウド上にシャドウ管理者アカウントを作成した場合、CI/CDログを設定変更やアイデンティティ変更と関連付けなければ見逃される可能性があります。また、過剰に広いOAuthスコープを持つサードパーティアプリが、侵害されたユーザーアカウントを通じてデータを外部に流出させた場合、真の侵入経路を明らかにできるのは、統合されたSaaSアクセスログとOAuth同意履歴だけです。
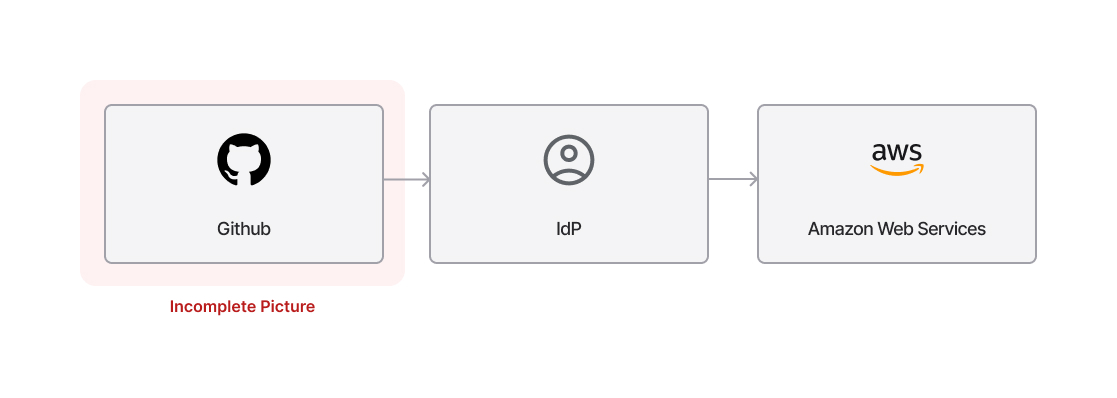
これらは抽象的な仮説ではありません。Salesloft/Driftの侵害では、攻撃者がまず侵害されたGitHubアカウントを介してアクセスを取得し、その後DriftのAWS環境でOAuthトークンを取得しました。攻撃者はそのトークンを使用し、信頼されたDriftとSalesforceのインテグレーションを通じて、接続されていた数百の顧客環境にアクセスしました。フォレンジックチームがGitHub、アイデンティティ、クラウド環境全体のアクティビティを相関分析するまでは、各プラットフォームのログは正常に見えていた可能性があります。
忠実度と決定性
データパイプラインの品質は、脅威ハンティングの忠実度を直接左右します。適切に構築されたデータパイプラインは、忠実度を損なうことなく重複を減らし、それによってコストも削減します。AI主導のシステムは、この忠実度に依存することで、確率的な推測ではなく決定的な回答を生成します。AIのパフォーマンス向上には、アーキテクチャ上の微調整よりも、データ品質の改善のほうが大きな効果をもたらします。検知と対応についても同じことが言えます。
脅威ハンティングの本質は、正確な問いを立て、信頼できる答えを得ることにあります。接続された高忠実度のデータ基盤がなければ、すべてのクエリは不完全なものになります。現代のセキュリティアーキテクチャでは、量よりも明確性を優先し、人間とマシンの双方が単一かつ正確な信頼できる情報源に基づいて動作できるようにする必要があります。
戦略的なストレージとAI対応
脅威ハンティングプラットフォームでは、どのデータをホットストレージに置き、どのデータをコールドストレージに置くかについても、戦略的である必要があります。すべてのログ、トレース、イベントを即座にクエリ可能にする必要はありません。重要なのは、アイデンティティ変更、クラウド設定、ソース管理アクティビティなどの高価値テレメトリに容易にアクセスできるようにしつつ、履歴データや低シグナルデータを、より詳細なフォレンジック用途に階層化できるようにすることです。ストレージ戦略が高度であるほど、アナリストとモデルは、無関係なノイズに計算リソースやコストを浪費することなく、より迅速に対応できます。
データがすべて1か所に集約されていると、LLMのユースケースにも自然に対応しやすくなります。堅牢なデータパイプラインは、効果的なコンテキストエンジニアリングの一形態です。Anthropicのエンジニアが示しているように、最良のAI成果は、適切なデータを、適切なタイミングで、適切なコンテキストとともに、ただし過剰にならないように提供するプラットフォームから生まれます。構造化され、関連性の高い情報セットをモデルに与えることで、不要な詳細に埋もれたり、重要な事実が不足したりすることなく、問題に対する推論に集中できるようになります。これは人間にも同じことが言えます。どれほど優れたアナリストであっても、ノイズに圧倒されたり、コンテキストが不足したりすれば、有効性は低下します。データパイプラインがコンテキストの精度を重視して設計されていれば、AI脅威ハンティングは真にスケールできるようになります。
インサイトを優位性へ変える
攻撃者の動きがかつてないほど速くなっている中で、勝つのは自社環境全体をリアルタイムで把握できる組織です。脅威ハンティングのためにAI対応のデータプラットフォームを構築することは、単に検知速度を高めるだけではありません。不確実性を理解へと変えることでもあります。統合データは統合された可視性を意味し、統合された可視性はプロアクティブな防御の基盤です。データエンジンが忠実度、スケール、AI対応に合わせて最適化されていれば、脅威ハンティングはより鋭く、より速く、より精密になります。






